【2025年最新】robots.txtを使ったクローラー最適化と効果的な設定方法

 ポスト
ポスト シェア
シェアSEOにおけるrobots.txtの役割は、クローラーの動きを効率化することで重要なページに集中させる、重複コンテンツを防ぐ、そしてサーバー負荷を軽減することにあります。本記事では、初心者向けにrobots.txtの基本構文、SEOに与える影響、設定例、注意点、さらに実際のサイトへの反映手順を解説します。

目次
robots.txtとは?その基本的な役割
robots.txtは、ウェブサイト上でクローラーがアクセスする範囲を制限または許可するためのシンプルなテキストファイルです。たとえば、以下のような記述をすることで、特定のディレクトリへのクローリングを制限できます。
User-agent: *
Disallow: /private/
- User-agent: 指示を適用するクローラーを指定。
*を使うと全クローラーに適用。 - Disallow: アクセスを禁止するディレクトリやページを指定。
- Allow: 特定のパスのみ許可する際に使用(Googlebotなど一部クローラーで利用可能)。
このようにrobots.txtを活用することで、クローラーの動きを管理し、サイト全体のクロール効率を高めることが可能です。
robots.txtとSEOの関係
SEOにおける主なメリット
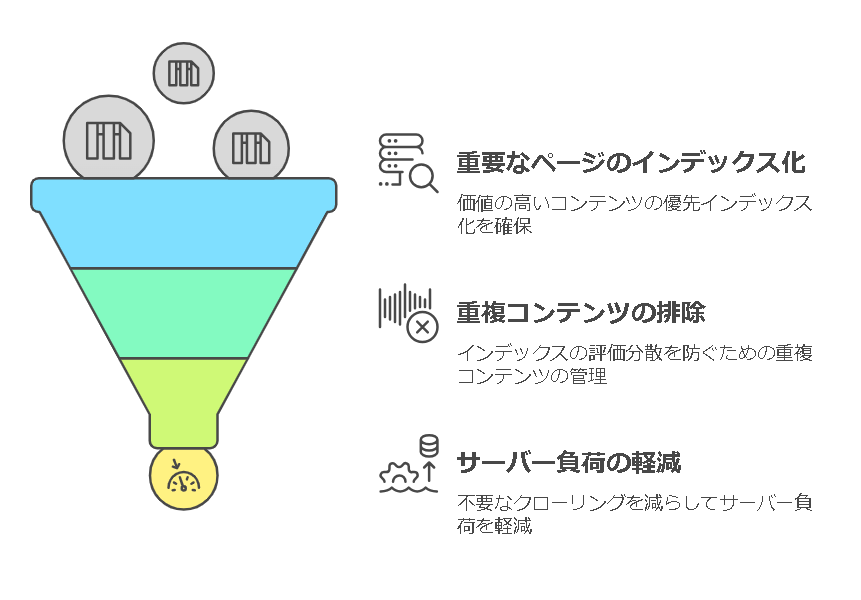
- クローラーの効率的な誘導
重要なページだけをクロールさせるよう指示することで、検索エンジンのリソースを有効活用。これにより価値の高いコンテンツがより早くインデックスされる可能性があります。 - 重複コンテンツの制御
同一の内容を持つ複数ページがある場合、それらをクローラーにインデックスさせないことで、検索エンジン内での評価分散を防止します。 - サーバー負荷の軽減
必要のないディレクトリやページへのクローリングを抑制し、サーバーへの負担を軽減します。
注意点
- インデックスの完全除外は保証されない
robots.txtは「クロール制御」のためのファイルであり、検索エンジンのインデックスから完全に削除する目的には向いていません。インデックスから除外したい場合は、noindexメタタグやHTTPヘッダーを使用する必要があります。 - Allowディレクティブの利用には注意
AllowディレクティブはGoogleなど一部のクローラーで機能しますが、すべての検索エンジンに適用されるとは限りません。そのため、特定の範囲を許可する際は事前にクローラーの挙動を確認しましょう。
robots.txtの基本構文と設定例
基本構文
User-agent: クローラー名
Disallow: 禁止したいパス
Allow: 許可したいパス(必要に応じて)
設定例
1.全ページをクロール許可
User-agent: *
Allow: /
2.特定ディレクトリをクロール禁止
User-agent: *
Disallow: /private/
Disallow: /temp/3.特定クローラーのみ制限
User-agent: Googlebot
Disallow: /nogoogle/4.サイトマップを指定
User-agent: *
Sitemap: https://www.example.com/sitemap.xmlrobots.txtの設置手順
ファイル作成
テキストエディタ(例: Notepad)を使用してrobots.txtを作成し、UTF-8で保存します。
ファイルの配置
サイトのルートディレクトリにrobots.txtをアップロードします。たとえば、https://www.example.com/robots.txtにアクセスして正しく表示されることを確認します。
Google Search Consoleでの検証
Search Consoleでクロールのエラーやインデックスの問題を確認し、robots.txtが期待どおりに機能しているかチェックします。
robots.txt設定後の実践的な確認方法と注意事項
クローラーの動作確認
更新したrobots.txtの内容が実際にクローラーによって認識されているか確認しましょう。
ファイル配置のチェック
robots.txtは必ずサイトのルートディレクトリに配置します。誤った場所に置いてもクローラーは認識できません。
定期的な更新とメンテナンス
サイトの構造が変わったり、新たなページが追加された場合は、robots.txtを更新して適切な指示を維持しましょう。
まとめ
robots.txtは、検索エンジンのクローラーに対してどのページをクロールすべきか、またどのページを除外するべきかを明確に示すための重要なツールです。適切な設定により、クローリングの効率化、重複コンテンツの防止、サーバー負荷の軽減を実現できます。
ただし、robots.txtはインデックスの完全除外には適さないため、機密情報の保護には別の方法を用いる必要があります。また、Google Search Consoleなどで定期的に確認し、設定が正しく機能していることを確認しましょう。
robots.txtを効果的に活用して、SEO戦略をより強固なものにしていきましょう!
検索順位、実は“技術的な設定ミス”で落としていませんか?
- 正しく設定しているつもりでも、多くの人が間違えている項目とは?
- SEO評価に影響する“見えない落とし穴”も意外と多い…
- 実は“1カ所の改善だけで順位が上がった”事例も
プロが教える、“テクニカルSEOを整える基本のチェックポイント”を聞いてみませんか?もっと詳しく知りたい方は、こちらをご覧ください。
この記事を読んだ方におすすめの記事はこちら
- プロフィール
-
- 経済学部。 オウンドメディア運用に向けSEO対策の情報やテクニックに関する記事を執筆。









